Get an email when there's a new version of AutoGluon
| Name | Modified | Size | Downloads / Week |
|---|---|---|---|
| Parent folder | |||
| README.md | 2025-04-30 | 29.7 kB | |
| v1.3.0 source code.tar.gz | 2025-04-30 | 3.3 MB | |
| v1.3.0 source code.zip | 2025-04-30 | 4.0 MB | |
| Totals: 3 Items | 7.3 MB | 0 | |
Version 1.3.0
We are happy to announce the AutoGluon 1.3.0 release!
AutoGluon 1.3 focuses on stability & usability improvements, bug fixes, and dependency upgrades.
This release contains 144 commits from 20 contributors! See the full commit change-log here: https://github.com/autogluon/autogluon/compare/v1.2.0...v1.3.0
Join the community: 

Loading models trained on older versions of AutoGluon is not supported. Please re-train models using AutoGluon 1.3.
Highlights
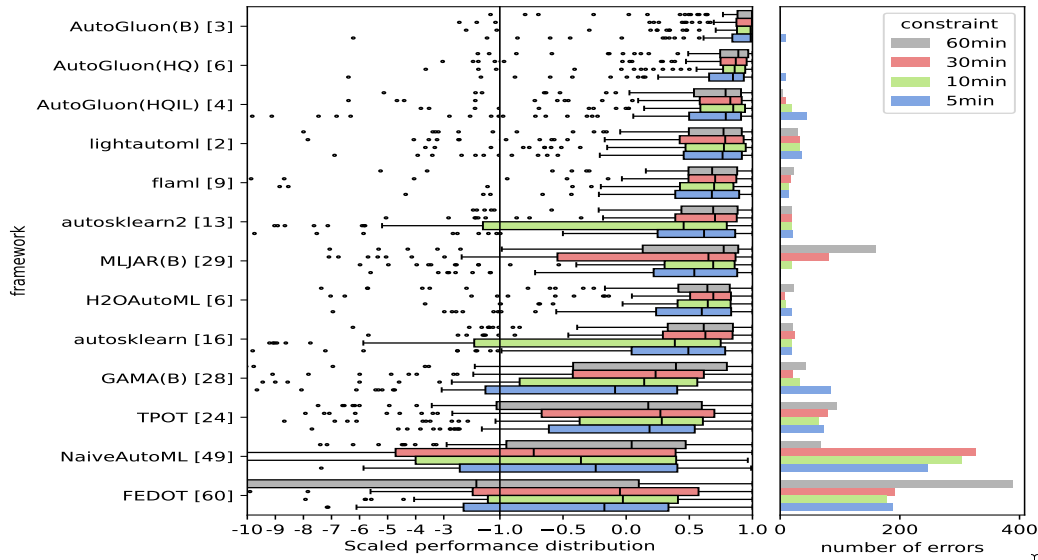
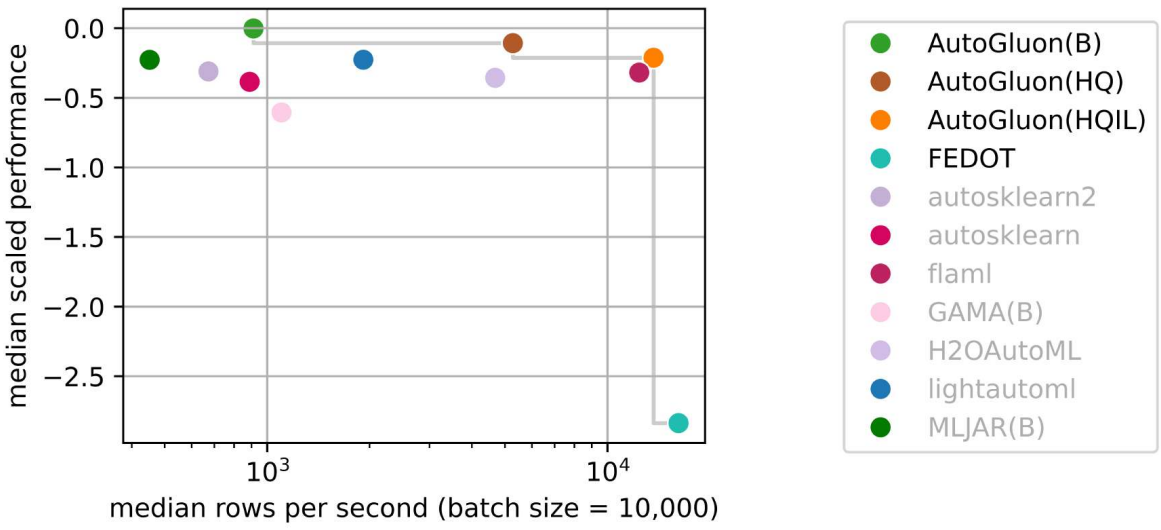
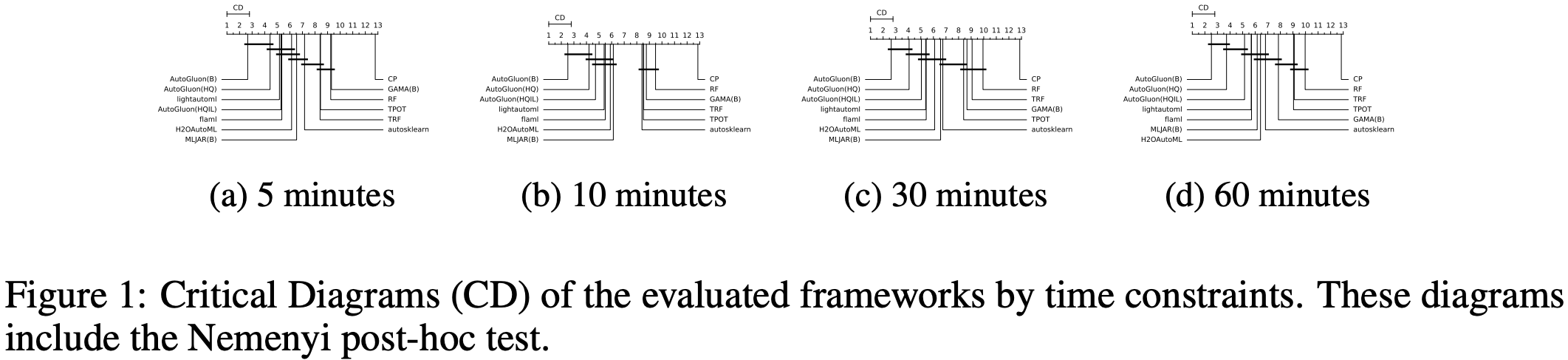
AutoGluon-Tabular is the state of the art in the AutoML Benchmark 2025!
The AutoML Benchmark 2025, an independent large-scale evaluation of tabular AutoML frameworks, showcases AutoGluon 1.2 as the state of the art AutoML framework! Highlights include:
- AutoGluon's rank statistically significantly outperforms all AutoML systems via the Nemenyi post-hoc test across all time constraints.
- AutoGluon with a 5 minute training budget outperforms all other AutoML systems with a 1 hour training budget.
- AutoGluon is pareto efficient in quality and speed across all evaluated presets and time constraints.
- AutoGluon with presets="high", infer_limit=0.0001 (HQIL in the figures) achieves >10,000 samples/second inference throughput while outperforming all methods.
- AutoGluon is the most stable AutoML system. For "best" and "high" presets, AutoGluon has 0 failures on all time budgets >5 minutes.
AutoGluon Multimodal's "Bag of Tricks" Update
We are pleased to announce the integration of a comprehensive "Bag of Tricks" update for AutoGluon's MultiModal (AutoMM). This significant enhancement substantially improves multimodal AutoML performance when working with combinations of image, text, and tabular data. The update implements various strategies including multimodal model fusion techniques, multimodal data augmentation, cross-modal alignment, tabular data serialization, better handling of missing modalities, and an ensemble learner that integrates these techniques for optimal performance.
Users can now access these capabilities through a simple parameter when initializing the MultiModalPredictor after following the instruction here to download the checkpoints:
:::python
from autogluon.multimodal import MultiModalPredictor
predictor = MultiModalPredictor(label="label", use_ensemble=True)
predictor.fit(train_data=train_data)
We express our gratitude to @zhiqiangdon, for this substantial contribution that enhances AutoGluon's capabilities for handling complex multimodal datasets. Here is the corresponding research paper describing the technical details: Bag of Tricks for Multimodal AutoML with Image, Text, and Tabular Data.
Deprecations and Breaking Changes
The following deprecated TabularPredictor methods have been removed in the 1.3.0 release (deprecated in 1.0.0, raise in 1.2.0, removed in 1.3.0). Please use the new names:
- persist_models -> persist, unpersist_models -> unpersist, get_model_names -> model_names, get_model_best -> model_best, get_pred_from_proba -> predict_from_proba, get_model_full_dict -> model_refit_map, get_oof_pred_proba -> predict_proba_oof, get_oof_pred -> predict_oof, get_size_disk_per_file -> disk_usage_per_file, get_size_disk -> disk_usage, get_model_names_persisted -> model_names(persisted=True)
The following logic has been deprecated starting in 1.3.0 and will log a FutureWarning. Functionality will be changed in a future release:
- (FutureWarning)
TabularPredictor.delete_models()will default todry_run=Falsein a future release (currentlydry_run=True). Please ensure you explicitly specifydry_run=Truefor the existing logic to remain in future releases. @Innixma (#4905)
General
Improvements
- (Major) Internal refactor of
AbstractTrainerclass to improve extensibility and reduce code duplication. @canerturkmen (#4804, #4820, #4851)
Dependencies
- Update numpy to
>=1.25.0,<2.3.0. @tonyhoo, @Innixma, @suzhoum (#5020, #5056, #5072) - Update spacy to
<3.9. @tonyhoo (#5072) - Update scikit-learn to
>=1.4.0,<1.7.0. @tonyhoo, @Innixma (#5029, #5045) - Update psutil to
>=5.7.3,<7.1.0. @tonyhoo (#5020) - Update s3fs to
>=2024.2,<2026. @tonyhoo (#5020) - Update ray to
>=2.10.0,<2.45. @suzhoum, @celestinoxp, @tonyhoo (#4714, #4887, #5020) - Update tabpfn to
>=0.1.11,<0.2. @Innixma (#4787) - Update torch to
>=2.2,<2.7. @FireballDWF (#5000) - Update lightning to
>=2.2,<2.7. @FireballDWF (#5000) - Update torchmetrics to
>=1.2.0,<1.8. @zkalson, @tonyhoo (#4720, #5020) - Update torchvision to
>=0.16.0,<0.22.0. @FireballDWF (#5000) - Update accelerate to
>=0.34.0,<2.0. @FireballDWF (#5000) - Update lightgbm to
>=4.0,<4.7. @tonyhoo (#4960) - Update fastai to
>=2.3.1,<2.9. @Innixma (#4988) - Update jsonschema to
>=4.18,<4.24. @tonyhoo (#5020) - Update scikit-image to
>=0.19.1,<0.26.0. @tonyhoo (#5020) - Update omegaconf to
>=2.1.1,<2.4.0. @tonyhoo (#5020) - Update pytorch-metric-learning to
>=1.3.0,<2.9. @tonyhoo (#5020) - Update nltk to
>=3.4.5,<4.0. @tonyhoo (#5020) - Update pytesseract to
>=0.3.9,<0.4. @tonyhoo (#5020) - Update nvidia-ml-py3 to
>=7.352.0,<8.0. @tonyhoo (#5020) - Update datasets to
>=2.16.0,<3.6.0. @tonyhoo (#5020) - Update onnxruntime to
>=1.17.0,<1.22.0. @tonyhoo (#5020) - Update tensorrt to
>=8.6.0,<10.9.1. @tonyhoo (#5020) - Update xgboost to
>=2.0,<3.1. @tonyhoo (#5020) - Update imodels to
>=1.3.10,<2.1.0. @tonyhoo (#5020) - Update statsforecast to
>=1.7.0,<2.0.2. @tonyhoo (#5020)
Documentation
- Updating documented python version's in CONTRIBUTING.md. @celestinoxp (#4796)
- Refactored CONTRIBUTING.md to have up-to-date information. @Innixma (#4798)
- Fix various typos. @celestinoxp (#4819)
- Minor doc improvements. @tonyhoo (#4894, #4929)
Fixes and Improvements
- Fix colab AutoGluon source install with
uv. @tonyhoo (#4943, #4964) - Make
full_install.shuse the script directory instead of the working directory. @Innixma (#4933) - Add
test_version.pyto ensure proper version format for releases. @Innixma (#4799) - Fix
setup_outputdirto work with s3 paths. @suzhoum (#4734) - Ensure
setup_outputdiralways makes a new directory ifpath_suffix != Noneandpath=None. @Innixma (#4903) - Check
cuda.is_available()before callingcuda.device_count()to avoid warnings. @Innixma (#4902) - Log a warning if mlflow autologging is enabled. @shchur (#4925)
- Fix rare ZeroDivisionError edge-case in
get_approximate_df_mem_usage. @shchur (#5083) - Minor fixes & improvements. @suzhoum @Innixma @canerturkmen @PGijsbers @tonyhoo (#4744, #4785, #4822, #4860, #4891, #5012, #5047)
Tabular
Removed Models
- Removed vowpalwabbit model (key:
VW) and optional dependency (autogluon.tabular[vowpalwabbit]), as the model implemented in AutoGluon was not widely used and was largely unmaintained. @Innixma (#4975) - Removed TabTransformer model (key:
TRANSF), as the model implemented in AutoGluon was heavily outdated, unmaintained since 2020, and generally outperformed by FT-Transformer (key:FT_TRANSFORMER). @Innixma (#4976) - Removed tabpfn from
autogluon.tabular[tests]install in preparation for futuretabpfn>=2.xsupport. @Innixma (#4974)
New Features
- Add support for regression stratified splits via binning. @Innixma (#4586)
- Add
TabularPredictor.model_hyperparameters(model)that returns the hyperparameters of a model. @Innixma (#4901) - Add
TabularPredictor.model_info(model)that returns the metadata of a model. @Innixma (#4901) - (Experimental) Add
plot_leaderboard.pyto visualize performance over training time of the predictor. @Innixma (#4907) - (Major) Add internal
ag_model_registryto improve the tracking of supported model families and their capabilities. @Innixma (#4913, #5057, #5107) - Add
raise_on_model_failureTabularPredictor.fitargument, default to False. If True, will immediately raise the original exception if a model raises an exception during fit instead of continuing to the next model. Setting to True is very helpful when using a debugger to try to figure out why a model is failing, as otherwise exceptions are handled by AutoGluon which isn't desired while debugging. @Innixma (#4937, #5055)
Documentation
- Minor tutorial doc improvements/fixes. @kbulygin @Innixma (#4779, #4777)
- Add Kaggle competition results. @Innixma (#4717, #4770)
Fixes and Improvements
- (Major) Ensure bagged refits in refit_full works properly (crashed in v1.2.0 due to a bug). @Innixma (#4870)
- Improve XGBoost and CatBoost memory estimates. @Innixma (#5090)
- Improve LightGBM memory estimates. @Innixma (#5101)
- Fixed plot_tabular_models save path. @everdark (#4711)
- Fixed balanced_accuracy metric edge-case exception + added unit tests to ensure future bugs don't occur. @Innixma (#4775)
- Fix HPO logging verbosity. @Innixma (#4781)
- Improve logging for use_child_oof=True. @Innixma (#4780)
- Fix crash when NN_TORCH trains with fewer than 8 samples. @Innixma (#4790)
- Improve logging and documentation in CatBoost memory_check callback. @celestinoxp (#4802)
- Improve code formatting to satisfy PEP585. @celestinoxp (#4823)
- Remove deprecated TabularPredictor methods: @Innixma (#4906)
- (FutureWarning)
TabularPredictor.delete_models()will default todry_run=Falsein a future release (currentlydry_run=True). Please ensure you explicitly specifydry_run=Truefor the existing logic to remain in future releases. @Innixma (#4905) - Sped up tabular unit tests by 4x through various optimizations (3060s -> 743s). @Innixma (#4944)
- Major tabular unit test refactor to avoid using fixtures. @Innixma (#4949)
- Fix XGBoost GPU warnings. @Innixma (#4866)
- Fix
TabularPredictor.refit_full(train_data_extra)failing when categorical features exist. @Innixma (#4948) - Reduced memory usage of artifact created by
convert_simulation_artifacts_to_tabular_predictions_dictby 4x. @Innixma (#5024) - Minor fixes. @shchur (#5030)
- Ensure that max model resources is respected during holdout model fit. @Innixma (#5067)
- Remove unintended setting of global random seed during LightGBM model fit. @Innixma (#5095)
TimeSeries
The new v1.3 release brings numerous usability improvements and bug fixes to the TimeSeries module. Internally, we completed a major refactor of the core classes and introduced static type checking to simplify future contributions, accelerate development, and catch potential bugs earlier.
API Changes and Deprecations
-
As part of the refactor, we made several changes to the internal
AbstractTimeSeriesModelclass. If you maintain a custom model implementation, you will likely need to update it. Please refer to the custom forecasting model tutorial for details.No action is needed from the users that rely solely on the public API of the
timeseriesmodule (TimeSeriesPredictorandTimeSeriesDataFrame).
New Features
- New tutorial on adding custom forecasting models by @shchur in #4749
- Add
cutoffsupport inevaluateandleaderboardby @abdulfatir in #5078 - Add
horizon_weightsupport forTimeSeriesPredictorby @shchur in #5084 - Add
make_future_data_framemethod to TimeSeriesPredictor by @shchur in #5051 - Refactor ensemble base class and add new ensembles by @canerturkmen in #5062
Code Quality
- Add static type checking for the
timeseriesmodule by @canerturkmen in #4712 #4788 #4801 #4821 #4969 #5086 #5085 - Refactor the
AbstractTimeSeriesModelclass by @canerturkmen in #4868 #4909 #4946 #4958 #5008 #5038 - Improvements to the unit tests by @canerturkmen in #4773 #4828 #4877 #4872 #4884 #4888
Fixes and Improvements
- Allow using custom
distr_outputwith the TFT model by @shchur in #4899 - Update version ranges for
statsforecast&coreforecastby @shchur in #4745 - Fix feature importance calculation for models that use a
covariate_regressorby @canerturkmen in #4845 - Fix hyperparameter tuning for Chronos and other models by @abdulfatir @shchur in #4838 #5075 #5079
- Fix frequency inference for
TimeSeriesDataFrameby @abdulfatir @shchur in #4834 #5066 - Fix minor CovariateRegressor bugs by @shchur in #4849
- Update docs for custom
distr_outputby @Killer3048 in #5068 - Minor documentation updates by @shchur in #4928 #5092
- Raise informative error message if invalid model name is provided by @shchur in #5004
- Gracefully handle corrupted cached predictions by @shchur in #5005
- Chronos-Bolt: Fix scaling that affects constant series by @abdulfatir in #5013
- Fix deprecated
evaluation_strategykwarg intransformersby @abdulfatir in #5019 - Fix time_limit when val_data is provided #5046 by @shchur in #5059
- Rename covariate metadata by @canerturkmen in #5064
- Fix NaT timestamp values during resampling by @shchur in #5080
- Fix typing compatibility for py39 by @suzhoum @shchur in #5094 #5097
- Warn if an S3 path is provided to the
TimeSeriesPredictorby @shchur in #5091
Multimodal
New Features
AutoGluon's MultiModal module has been enhanced with a comprehensive "Bag of Tricks" update that significantly improves performance when working with combined image, text, and tabular data through advanced fusion techniques, data augmentation, and an integrated ensemble learner now accessible via a simple use_ensemble=True parameter after following the instruction here to download the checkpoints.
- [AutoMM] Bag of Tricks by @zhiqiangdon in #4737
Documentation
- [Tutorial] categorical convert_to_text default value by @cheungdaven in #4699
- [AutoMM] Fix and Update Object Detection Tutorials by @FANGAreNotGnu in #4889
Fixes and Improvements
- Update s3 path to public URL for AutoMM unit tests by @suzhoum in #4809
- Fix object detection tutorial and default behavior of predict by @FANGAreNotGnu in #4865
- Fix NLTK tagger path in download function by @k-ken-t4g in #4982
- Fix AutoMM model saving logic by capping transformer range by @tonyhoo in #5007
- fix: account for distributed training in learning rate schedule by @tonyhoo in #5003
Special Thanks
- Zhiqiang Tang for implementing "Bag of Tricks" for AutoGluon's MultiModal, which significantly enhances the multimodal performance.
- Caner Turkmen for leading the efforts on refactoring and improving the internal logic in the
timeseriesmodule. - Celestino for providing numerous bug reports, suggestions, and code cleanup as a new contributor.
Contributors
Full Contributor List (ordered by # of commits):
@Innixma @shchur @canerturkmen @tonyhoo @abdulfatir @celestinoxp @suzhoum @FANGAreNotGnu @prateekdesai04 @zhiqiangdon @cheungdaven @LennartPurucker @abhishek-iitmadras @zkalson @nathanaelbosch @Killer3048 @FireballDWF @timostrunk @everdark @kbulygin @PGijsbers @k-ken-t4g
New Contributors
- @everdark made their first contribution in #4711
- @kbulygin made their first contribution in #4777
- @celestinoxp made their first contribution in #4796
- @PGijsbers made their first contribution in #4891
- @k-ken-t4g made their first contribution in #4982
- @FireballDWF made their first contribution in #5000
- @Killer3048 made their first contribution in #5068
