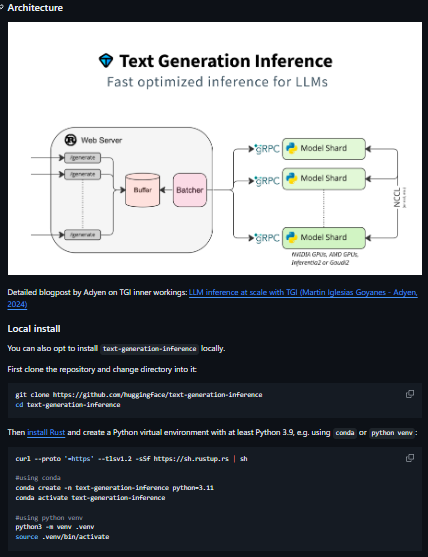
Text Generation Inference is a high-performance inference server for text generation models, optimized for Hugging Face's Transformers. It is designed to serve large language models efficiently with optimizations for performance and scalability.
Features
- Optimized for serving large language models (LLMs)
- Supports batching and parallelism for high throughput
- Quantization support for improved performance
- API-based deployment for easy integration
- GPU acceleration and multi-node scaling
- Built-in token streaming for real-time responses
Project Samples
License
Apache License V2.0Follow Text Generation Inference
Other Useful Business Software
Cut Cloud Costs with Google Compute Engine
Save on compute costs with Compute Engine. Reduce your batch jobs and workload bill 60-91% with Spot VMs. Compute Engine's committed use offers customers up to 70% savings through sustained use discounts. Plus, you get one free e2-micro VM monthly and $300 credit to start.
Rate This Project
Login To Rate This Project
User Reviews
Be the first to post a review of Text Generation Inference!
